



If you’ve been following my journey, you might know that I recently bought an M2 Max MacBook Pro. However, I also own a 2019 Intel MacBook Pro, which started to slow down significantly in recent days. Thankfully, I was able [Read More…]
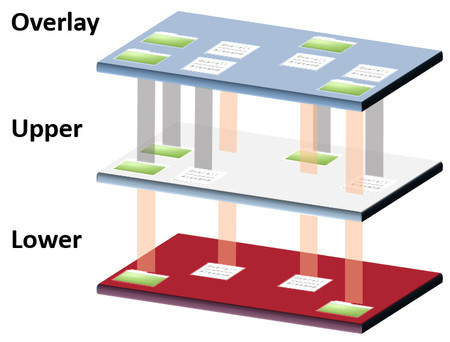
Overlay Union Filesystems in Linux
Returning to the world of blogging after nearly a month’s hiatus, I find myself intrigued by the concept of Overlay Filesystems. This article has piqued my curiosity, and I am convinced it will offer valuable insights for my future endeavors. [Read More…]




{kind=link}
{kind=link}
{kind=link}
{kind=link}