An Aficionado Journey in Opensource & Linux – And now It's a FinTech touch!
Assign a process to a specific CPU in a NUMA node
Linux & BSD systems, Applications and Security
Published: 2023-12-28 15:42:48
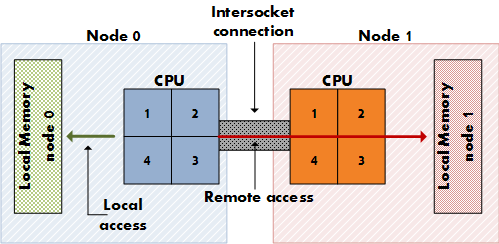
NUMA - Non-Uniform Memory Access is really about CPU topology - A map of how CPUs are associated with memory, hence that's why we say memory is divided into multiple memory nodes in NUMA. It's kind of multiple computers compacted together to build one. QPI - Quick Path Interconnect which is a 5-layer architecture is one of the technologies invented by Intel that provide high-speed, point-to-point links inside and outside of the processor.
UMA
Before moving on, it's also good to know that UMA - Uniform memory access is where all memory capacity and access time are equally accessed by all CPUs, whether the CPU is doing a task or not - which is usually in older x86 systems(Shared memory). So, memory blocks are accessed uniformly by all processing units, wherever the data is, which has its disadvantages like latency. Whether the memory is used or not, when the CPU is busy processing data, all memory will feel the latency in the system. Another problematic situation can be where multiple CPUs access the shared memory over a single BUS resulting in a Bus contention problem.
So why NUMA is needed?
However, in new x86 systems, memory is divided into zones, and it's called nodes. Each node is connected to a particular CPU or Socket. Imagine a cluster of physical hosts where local memory is accessing remote CPUs on a different host over a network! So, the memory that accesses the local CPUs is usually faster than remote CPUs(Distributed memory). This means that the more we need access to remote memory the more it costs, and the more we can use local memory the faster the system is which means it is more scalable by nature. Since we moved from UMA to NUMA, many software needs to adapt to that ecosystem. Most of the time, software optimization is needed. That does not necessarily mean that NUMA is always needed. Some software is designed without taking into consideration the NUMA at all. That's why sometimes, it's good to test and observe before enabling or disabling NUMA. Also good to know that, NUMA performance increases when more CPU is added.
NUMA policies
There are 4 types of NUMA policy in the RHEL world. Each policy defines how memory will be allocated from a node:
Interleave policy(Default): Memory pages are allocated in a round-robin manner across the nodes that have been allocated by a nodemask.
This means that the system will try to distribute memory evenly across all NUMA nodes.
Local policy(Prefer): When a process requests memory, memory is allocated from the node of the CPU running the process.
In this policy, memory is allocated locally to the processor that requests it. If local memory is not available, memory from a remote node is used.
Interleave policy(Scatter): Memory pages are allocated in a round-robin manner across the nodes that have been allocated by a nodemask.
This policy allocates memory in a round-robin fashion across NUMA nodes. It cycles through nodes circularly when allocating memory.
Preferred policy(Bind): Memory is allocated from a single preferred memory node. When memory is unavailable, memory will be allocated from other nodes.
In the strict policy, memory is bound to a specific NUMA node. Memory allocations are limited to the specified node, and the system does not attempt to use memory from other nodes.
numactl and numastat utility
The numactl utility will show you the total memory size, free memory, and CPUs displayed for each memory node. For this article, I have deployed a virtual machine configured with 8 CPUs and 10GB RAM.
1. To get the numactl and numastat on the Rocky Linux, install the numactl utility:
yum install numactl numactl-libs
2. To see the number of nodes and CPUs and Memory, do the following:
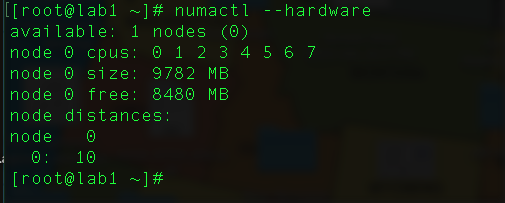
numactl --hardware
As you can see, there is only 1 node, and all CPUs are by default configured in that only 1 node with a total of 9782 MB, and out of the 9782 MB, 8480 MB is free and ready to be consumed by CPUs
3. Another command is numastat. This will give statistics about memory allocated to Numa nodes. Remember, each time the counter increments by 1, it represents one page of memory.
numa_hit - Number of allocations for a node that succeeded.
numa_miss - An allocation failed and was allocated somewhere else due to low memory.
numa_foreign - An allocation ended up with memory from a foreign node.
interleave_hit - An allocation that works in a round-robin fashion has succeeded.
local_node - Allocation is happening on the same local node from a local process.
other_node - Allocation on another node is allocation memory for the other node.
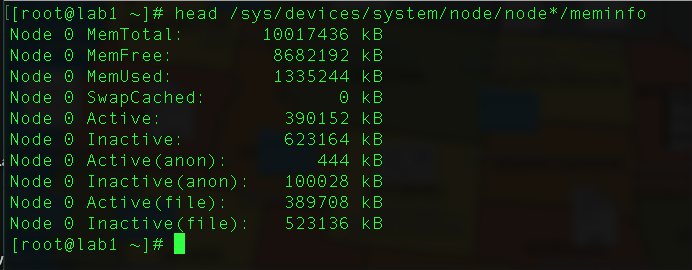
4. To get information about the numa node state of memory, it's useful to check the /sys/devices/system/node/node*/meminfo
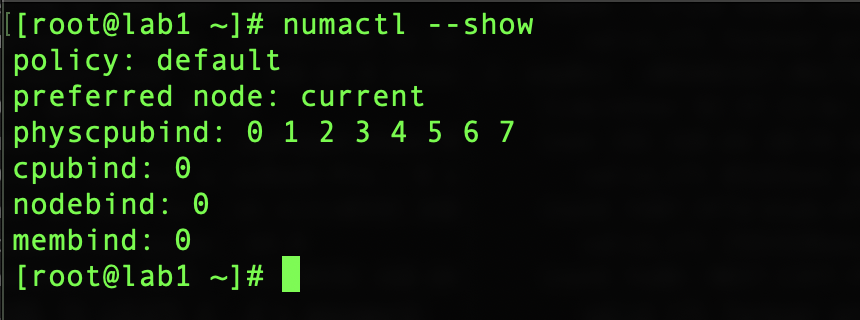
5. To identify which policy has been configured do a:
numactl --show
6. Setting up the kernel parameters to be able to use NUMA. In the /etc/default/grub, I added the parameter "numa=on"
7. Then, regenerate the grub config file:
grep GRUB_CMDLINE_LINUX /etc/default/grub
8. As you can see, I have only 1 node in this lab server and this is not an actual physical server, it's a virtual machine on my VMware physical ESXi lab.
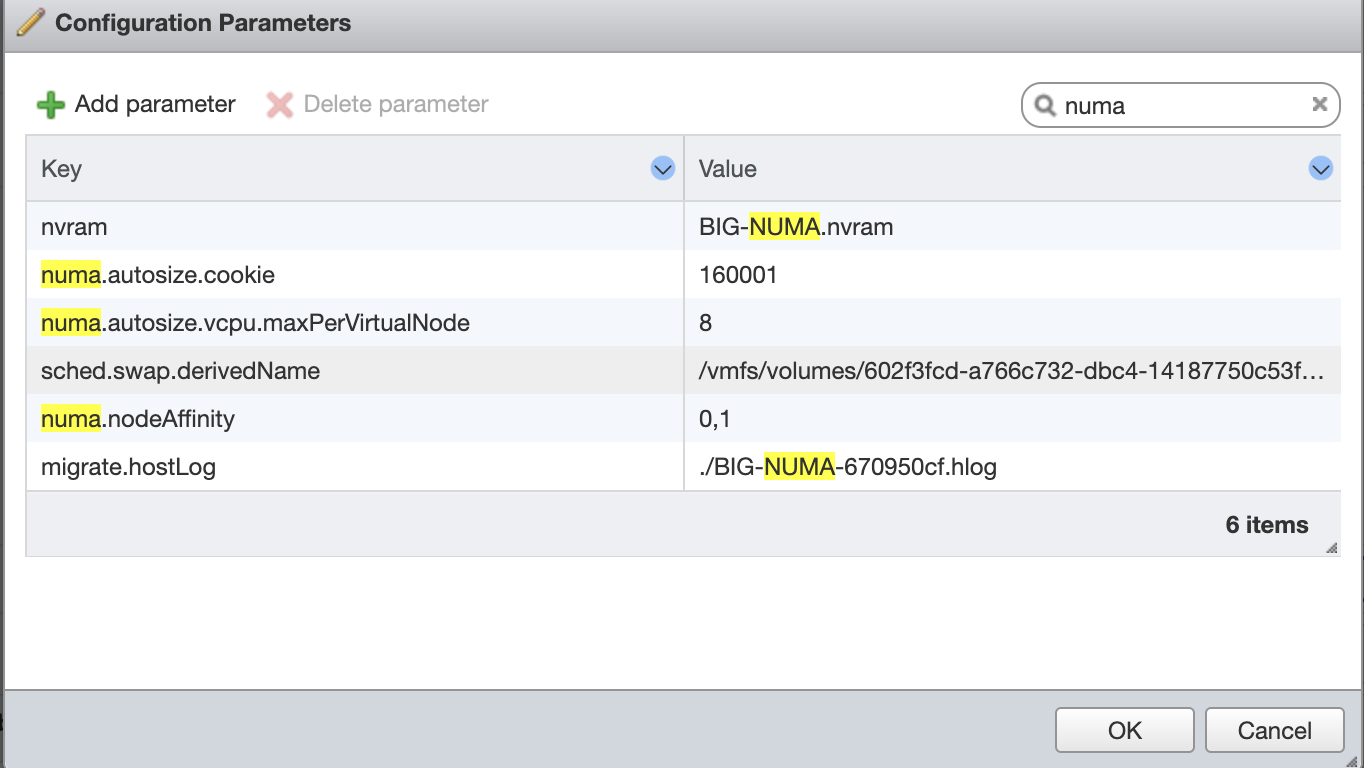
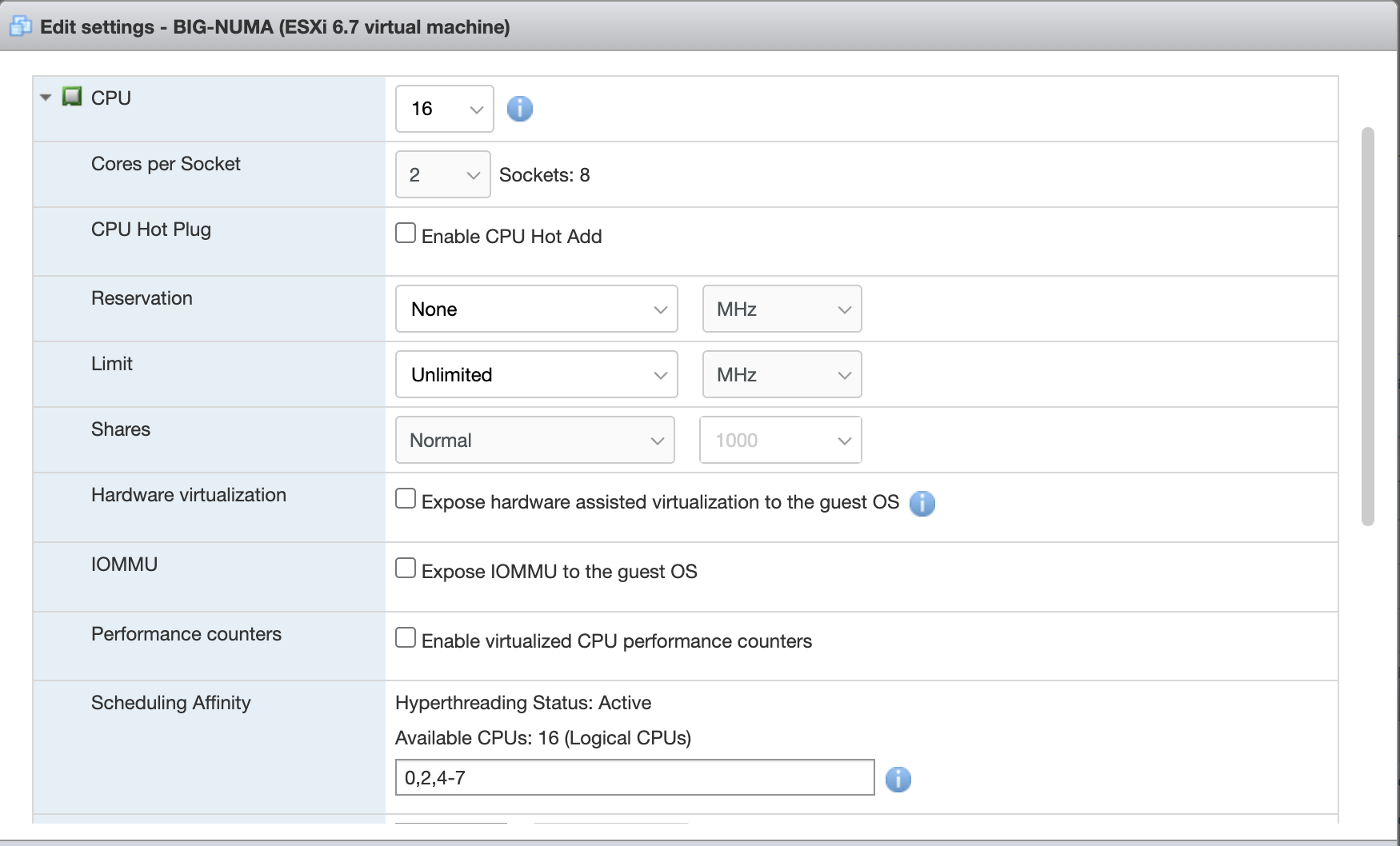
9. Changing some settings on VMWare (Edit the VM -> CPU Settings -> VM options -> Advanced ->Edit Configuration)
Then I added the parameter numa.nodeAffinity 0,1
I have also configured the Cores per Socket and set the affinity
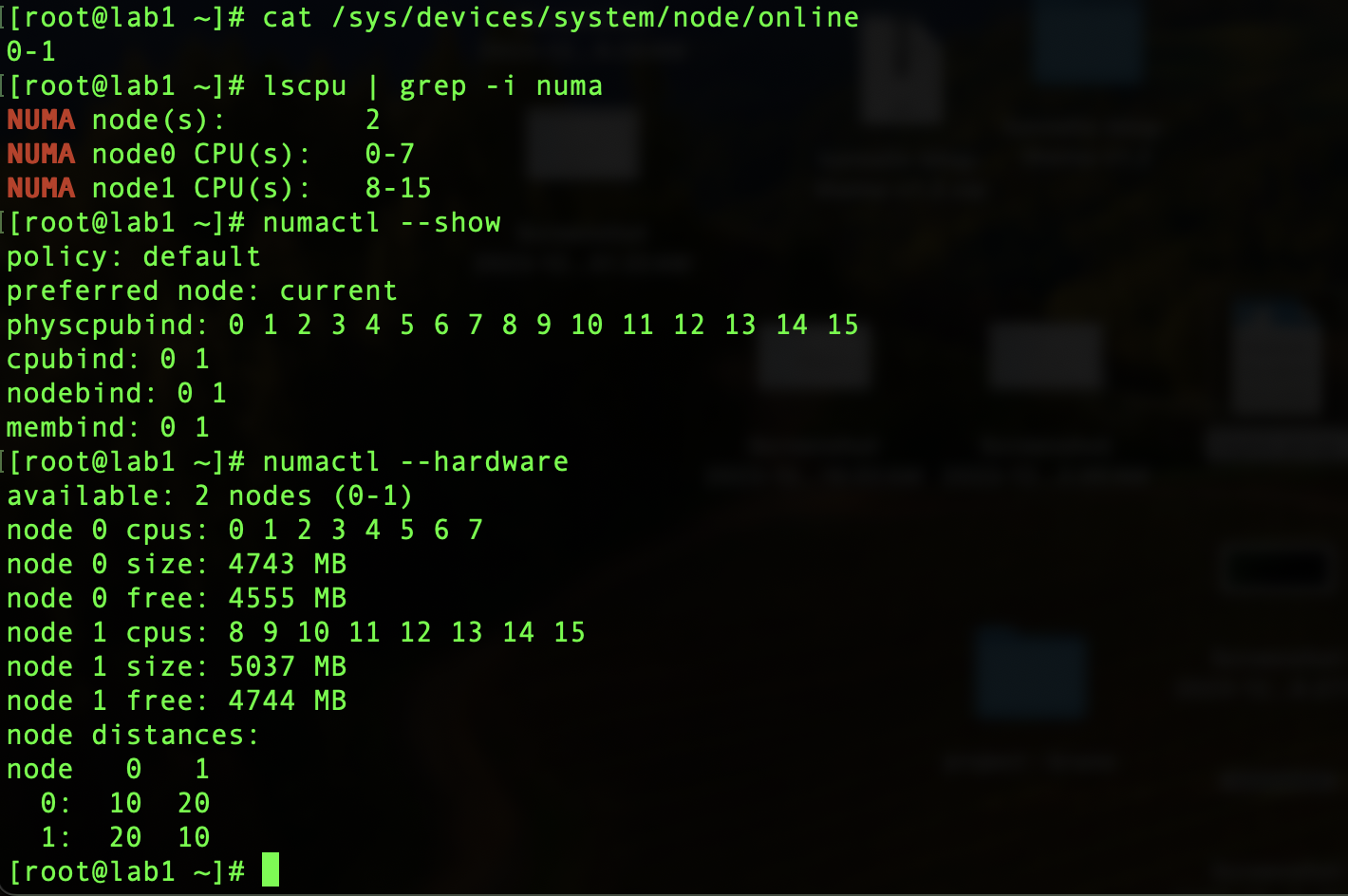
10. After the reboot, I can see the number of nodes that came online together with the CPU pinning in the node. These commands were pretty useful in identifying the nodes and the online status:
11. I have installed a Nginx web server for this demo. Let's say we want to run Nginx on a specific processor, say core 7 and --membind=1 , you want to use the memory from node 1. It can also be checked with a ps command:
The choice between UMA and NUMA depends on factors such as system size, scalability requirements, and the nature of the workloads running on the system. NUMA architectures are often preferred for large-scale multiprocessor systems where scalability and reduced contention are critical.
In my lab, since this is on VMware there are some limitation as the kernel need to be more NUMA aware.