An Aficionado Journey in Opensource & Linux – And now It's a FinTech touch!
Crash blog to start with Kubernetes - Microservices, Docker and Kubernetes - Part2
Linux & BSD systems, Applications and Security
Published: 2020-06-06 17:31:19
In the previous blog post, we went directly into the installation and configuration of a Kubernetes cluster. In this one, we will get into some details into the fundamentals and some explanations. On of the challenging topic are Microservices, Docker, and Kubernetes.
Microservices
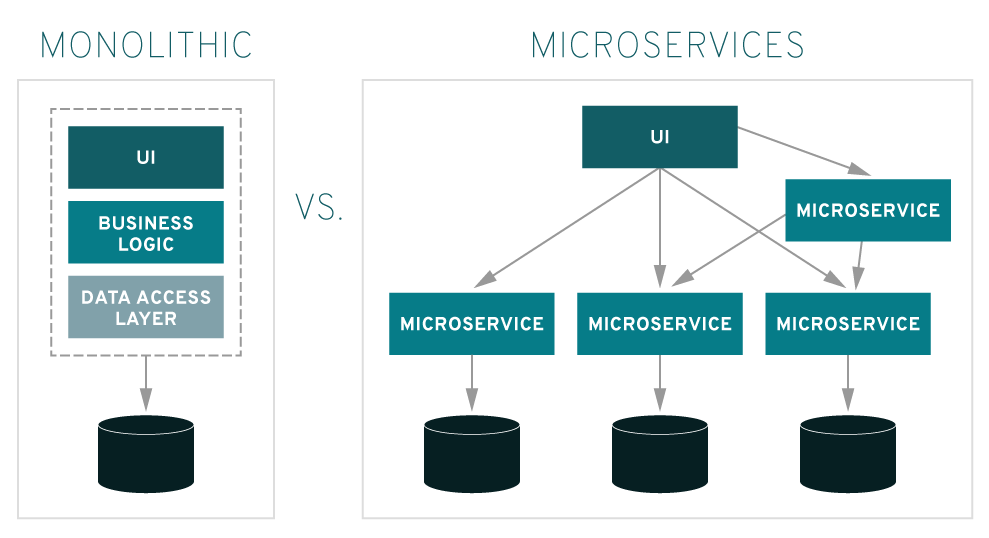
Microservices - A microservice can be referred to as an architecture style or methodology that structures an application as a collection of services that can be made independent. Instead of having a big monolith application, it is split into services and processes. For example, a web application has authentication, login, user management is split into different processes to communicate together using HTTPS or TLS.
[caption id="attachment_4784" align="aligncenter" width="989"] Monolith VS Microservices - Photo credits: redhat.com[/caption]
Some advantages
So, this is where Kubernetes comes into the picture. It is a container-orchestration system for automating application deployment, scaling, and management by using the microservices style. Some of the advantages of Kubernetes are:
Reliable language inter-dependency - Let's say an application has been written into Java, and another using GoLang, and they can communicate over HTTPS and talk to each other correctly, there will be no issue.
Working in teams - Let's say one team is working into Python, and the other in GoLang. This way specialization occurs and responsibilities are shared correctly. Compared to a monolith approach everything is interdependent.
Fault debugging and identification - Of course, when services are split up, faults are identified more rapidly. Isolation is very fast when using microservices. We can also swap over to a different microservice that will share the responsibility for the failure.
So just imagine, a microservice running in a docker container and sometimes, it needs more resources and sometimes not, hence, it makes scalability becomes very fast and efficient without downtime.
We also have disadvantages when running microservices
Just imagine, many microservices depending upon many others, it can be complex to debug and trace out where are the issue. Complexity is the issue here. Documentation is important. To trace from point A to Z is very hard and in terms of knowledge and architecture, it's very important to understand the whole containerization. In the monolith approach, this situation would be easier to solve.
Docker
Docker allows you to build, ship, and run distributed applications whether on bare metal or virtual machines. Applications are now coming as microservices and that's why it the important to learn Docker and Kubernetes. Containers are where the distribution applications are deployed. Kubernetes will orchestrate the distributed application. The idea is that the Docker container will contain the image and Kubernetes will orchestrate it.
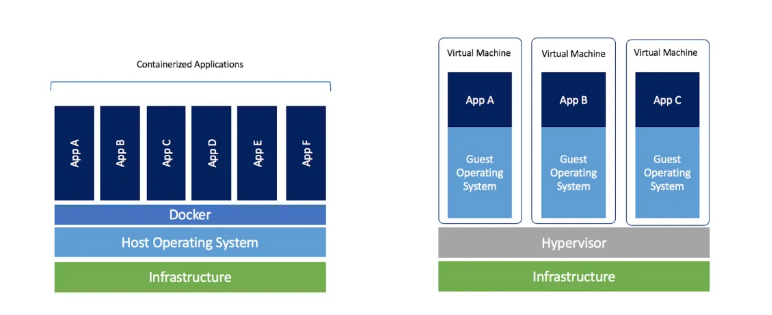
Something that I saw very confusing from many, is that a container is not a virtual machine. A virtual machine provides an abstract machine that uses device drivers targeting the abstract machine, while a container provides an abstract OS.
They might share the same principles, but they are different. In a VM, we have the entire packages such as the binaries, libraries, etc.. whereas, on the Docker, it is just the translation that goes on using the same binaries. With Docker, more space is saved whereas, on VMs, we are not cutting down on size.
To create a Docker image, we define it in the Dockerfile. In this article, I gave more ideas on how to build the image.
Kubernetes
There are many more container orchestration tools. One of them is Kubernetes. We have seen the installation and configuration of a Kubernetes cluster in the article: Crash blog to start with Kubernetes installation and configuration part1.
So, before going further, there are some key terms to get familiar with. Let's see them individually:
Node:
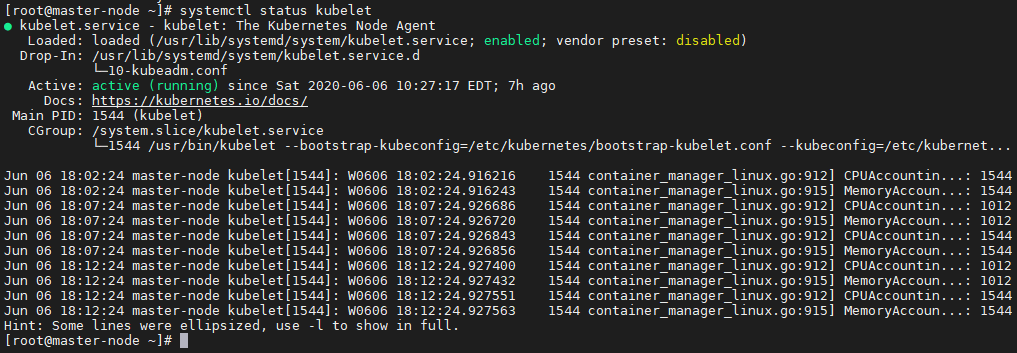
A node is an instance of a machine that is running Kubernetes. For example, in this article, master-node, worker-node1 and worker-node2 are nodes. They ran Kubelet. Kubelet is responsible to talk to the master-node and vice versa.
At step 9 in the previous article before running kubeadm join, systemctl would show that the service kubelet is down.
Pod:
And a node runs pods. A pod contains one or more containers. Pods are run on nodes.
Service Requests:
A service handles requests either coming from inside the Kubernetes cluster from one node/s to another. A service can also be routed from outside the network/cluster that will hit the microservice.
A deployment defines the desired state. For example, if we want 5 copies of a specific container in the Kubernetes cluster, Kubernetes will take care of the rest.
Controller:
Kubernetes controller or the master-node will contain the replication controller that will ensure that the copies of the pods are present and running. It also keeps a history of whatever happens in the pods. For example, you initially deployed 5 copies of a pod and then changed to 10. It will keep that in mind. A deployment file is usually YAML in nature though it can be written in JSON as well. I would use YAML because it is very human-readable and the same as the Ansible Playbook structure. Cool right?
Kube Proxy:
The intra-communication between pods on the worker nodes is handled by the Kube proxy.
Kube API server
This is responsible for all communication between the workers and the master.
Kube Scheduler
This is responsible to orchestrate what microservices or docker containers need to be run on which pods. It can be resource criteria such as CPU or RAM.
Remember, as a good principle of a robust platform, always have more than one master which ensures robustness and redundancy.
We can also use Kubernetes to roll new updates and reboot a container if something crashes. The way updates are handles there is no downtime.
I hope this article is useful and it helps. In the next article, I will focus on the deployment of the Kubernetes master and two nodes using Ansible. We will also see how to build two masters and three workers.
Sources: