

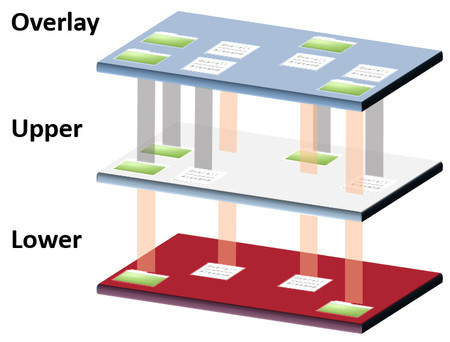
Returning to the world of blogging after nearly a month’s hiatus, I find myself intrigued by the concept of Overlay Filesystems. This article has piqued my curiosity, and I am convinced it will offer valuable insights for my future endeavors. [Read More…]
Counter DNS Attack: Enabling DNSSEC
To reach another person on the Internet you have to type an address into your computer – a name or a number. That address has to be unique so computers know where to find each other. ICANN coordinates these unique [Read More…]




{kind=link}
{kind=link}
{kind=link}
{kind=link}